
Anyone who has spent time working on cloud ETL pipelines knows that the biggest problems aren’t the ones that cause your jobs to fail, they’re the quiet ones that slip through unnoticed. AWS Glue is a powerful tool, but it doesn’t tell you when your data is subtly wrong. In this article, I walk through a validation approach I’ve built and refined over the years, combining practical QA techniques with lightweight AI to detect tricky issues like schema drift, misaligned fixed-length records, and odd shifts in how the data behaves over time. Everything here comes from real projects in healthcare and large enterprise environments where data quality matters a lot more than a green “SUCCESS” message in the logs.
Authors: Srikanth Kavuri, Senior Software QA Automation Engineer (AI-Driven Healthcare and cloud based Systems), https://www.linkedin.com/in/srikanth-kavuri-0937b9132/
1. Introduction
If you’ve ever been responsible for validating an ETL pipeline, you’ve likely felt that uneasy moment when everything “looks fine,” yet something in your gut says, “Something is off.” I’ve had jobs in AWS Glue that ran cleanly from start to finish, only for a downstream report to blow up the next morning because someone upstream changed a field or shifted the way a fixed-length file was formatted.
And this is the real problem Glue handles transformations, but it doesn’t verify the correctness of the data. Many teams assume it does, and that leads to silent data corruption.
This article lays out an approach that testers and engineers can use to guard against these kinds of issues. It’s not theoretical I’ve used versions of this framework in real production settings, and it’s saved me (and the teams I’ve worked with) from countless headaches.
2. Background and Context
2.1 The Nature of Today’s Pipelines
Modern ETL pipelines are rarely simple. Most pull from several upstream applications some stable, some unpredictable. Healthcare, for example, often deals with old formats (2264-byte encounter files) living alongside newer JSON or parquet streams. A single upstream “enhancement” can cause ripples that break everything in sight.
2.2 Why Traditional Testing Isn’t Enough
If your testing tool set consists of row counts, null checks, and a couple of joins, you’re going to miss the things that really cause problems. I’ve seen:
- service dates quietly shifted because of time zone normalization
- IDs lose leading zeros because they were cast incorrectly
- entire sections of fixed-length files shift because someone added a space in the wrong place
- lookup tables drift out of alignment with the data
None of these cause Glue to fail. But all of them produce incorrect results.
2.3 Why Some Domains Are More Fragile Than Others
Healthcare is the best example I can think of. A 2264-byte record is unforgiving. If even one byte moves out of place, dozens of fields that come after it lose their meaning. It’s like knocking over the first domino in a line of 100. Without a pre-ETL validator, you may never know it happened.
3. What Problem Are We Actually Solving?
The core issue is simple: AWS Glue doesn’t know your business rules, and it doesn’t protect you from subtle data issues.
Glue treats:
- type correction issues
- hidden whitespace
- dropped characters
- new category values
- fixed-length formatting problems
as minor inconveniences. It doesn’t complain, but your downstream analytics will.
What’s missing is a system that checks the data deeply before and after Glue runs to spot issues that SQL alone won’t catch.
4. The Framework That Actually Works
Below is the basic shape of the validation architecture I’ve had the most success with. It’s not fancy, but it’s reliable.
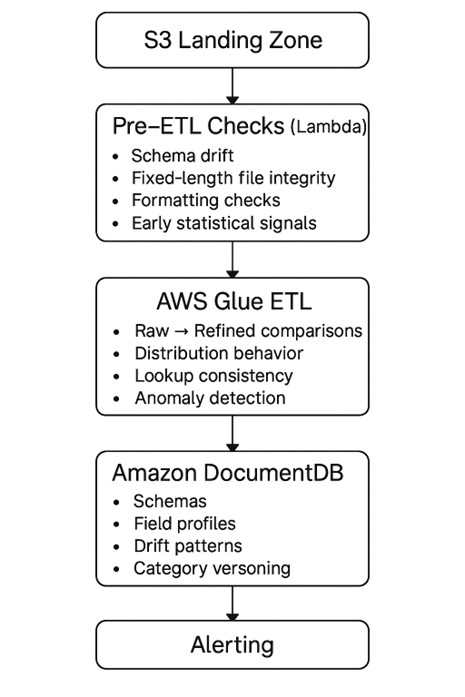
Alerting DocumentDB serves as the historical memory here. It holds schemas, field definitions, old lookup sets, and drift histories so we always have something to compare against.
5. How Validation Actually Works
5.1 Schema Drift Detection with DocumentDB
Every time a new file arrives, I extract its schema and compare it with the most recent version stored in DocumentDB. Because it’s JSON-based, storing multiple schema versions is painless.
The validator looks for:
- fields appearing or disappearing
- type shifts (like string → int)
- changes in field length or format
- semantic differences (e.g., a date field suddenly containing month names)
Sometimes these changes are harmless. Other times, they break the entire transformation logic. To cut down on false alarms, I rely on a simple machine-learning classifier that looks at historical field behavior to decide whether a drift is expected or unusual.
5.2 Validating 2264-Byte Healthcare Records
Here’s what I check before the data even touches Glue:
- Line length must be exactly 2264 bytes
- Every field must begin and end at the right offset
- Numeric fields should be left-padded with zeros
- Alphanumeric fields must be right padded with spaces
- Only printable ASCII should be allowed
- No control characters are usually signs of upstream encoding issues
To improve accuracy, I use an AI model that teaches the typical values inside each field. For example, if a field normally contains two-digit state codes and suddenly I see unexpected long strings, I know something is wrong.
5.3 Checking Glue’s Output with a Mix of SQL and ML
Once Glue finishes its work, I compare the output with raw data. Not at a superficial level but at a behavioral level.
Here’s what I mean:
Deterministic Checks (SQL)
- verify transformations
- check for truncation
- confirm cast behavior
- validate joins
Statistical Checks
These catch things SQL will never notice:
- PSI to identify distribution shifts
- seasonal trends in date fields
- unexpected spikes in nulls
Anomaly Detection (AI)
I use:
- Isolation Forest for numeric jumps
- Random Cut Forest for time-based anomalies
- Levenshtein distance for string format changes
This combined method has helped me catch issues that would have taken hours to debug manually.
5.4 Tracking Lookup Table Drift
Lookups change more often than people admit. And they almost always break silently.
To track drift, I compare category sets using Jaccard similarity. DocumentDB keeps past lookup versions, so I can see exactly when new codes appeared or old ones dropped out.
If similarity dips too low, I know something significant has changed.
6. Real Examples from the Field
Example 1: Leading Zeros Gone Wrong
Glue casts a provider ID field into an integer. Overnight, thousands of IDs changed shape. Only a drift check caught it.
Example 2: The One-Byte Disaster
A single extra space in a fixed-length file shifted the offsets for almost every field downstream. The file “looked fine,” but a positional validator proved otherwise.
Example 3: New Provider Codes Introduced Without Notice
Jaccard similarity plummeted. Turns out new specialty codes were added upstream without updating the lookup table.
Example 4: Date Seasonality Drift
A monthly batch contained dates that completely ignored expected patterns PSI flagged it before the ETL job reached production.
7. What Changed After Implementing This Framework
Across multiple teams, I’ve seen the following:
- Reprocessing dropped significantly
- Most silent data issues were caught before Glue ran
- Debugging time decreased drastically
- Testers gained more confidence in Glue outputs
- Automation became easier because metadata lived centrally
- AI filtered out false positives that used to waste hours
This isn’t a silver bullet, but it’s the closest thing I’ve found to a safety net.
8. How This Compares to Traditional Testing
Traditional ETL testing focuses almost entirely on SQL logic. But SQL won’t tell you:
- whether fixed-length files misaligned
- whether lookup values drifted
- whether a date column’s behavior changed
- whether a field shifted from free text to integers
- whether casts silently failed
The framework in this article looks at behavior, not just structure, which gives testers a much deeper signal.
9. Practical Tips and Lessons Learned
- Never assume a schema will stay the same even within a single business week.
- Keep every schema version and lookup set in DocumentDB.
- Validate fixed-length files before Glue touches them.
- Use distribution-based checks instead of fixed thresholds.
- Let AI separate real issues from noise, especially in large datasets.
- Always review drift in context; not all change is bad.
10. Conclusion
AWS Glue is great at moving and transforming data, but it wasn’t built to catch the subtle issues that matter the most. After working on several healthcare and enterprise pipelines, I’ve learned that having a thoughtful validation layer one that watches for drift, anomalies, and formatting problems can save hours of debugging and prevent costly downstream errors. AI isn’t replacing testers; it’s giving us better tools so we can focus on the issues that matter. And as data pipelines continue growing in complexity, having this kind of framework in place becomes less of a luxury and more of a necessity.
About the Author
My name is Srikanth Kavuri, and I’ve spent more than a decade working as a Senior Software QA Automation Engineer across healthcare, insurance, and large enterprise environments. I specialize in ETL testing, AI-assisted automation, and designing validation frameworks that keep complex data pipelines honest.
Good post about ETL testing! We will be linking to this particularly great post on our site. Keep up the great writing
Very interesting article providing expert knowledge, especially the part about checking Glue output with a mix of SQL and ML.