
In performance testing, you need a lot of data to get results that are meaningful for a production context. In this article, Sudhakar Reddy Narra explains why you should not just focus on the quantity, but also on the quality of the data that you are going to use in your tests.
Author: Sudhakar Reddy Narra, https://www.linkedin.com/in/sudhakar-reddy-narra-05751655/
When most people hear Performance Testing they picture virtual users hammering APIs while graphs track response times. That is just one part of the story, but not the whole thing. The real performance issues do not just come from how many users you simulate , but they come from the data those users are working with. If your test data is too clean, too uniform, or just plain unrealistic data, your system will look fine in staging and then fall apart under the real production workloads.
The trouble is that production data is usually off limits for performance testing. Security, privacy, and compliance rules mean you can not just clone the production database and hand it for performance testing. That is where synthetic data comes in. If you do it right, it behaves like production data : varied, skewed, multilingual, full of quirks , without exposing anything sensitive. Done wrong, it gives you a false sense of safety in your load test.
In this article, I will walk through how to generate synthetic datasets that actually mimic production. The key is to stop thinking in terms of raw record counts and start modeling the shape of data, the distributions, the hot spots, the time bias, the uniqueness rules, and the way people actually search. Along the way, I will use Python’s Faker and NumPy libraries, but the principles work no matter which tools you use.
1. Data Shape Matters More Than Record Count
Too many teams brag about we loaded 10 million rows into our test environment, but forget to ask what those rows look like. Shape is everything, high cardinality vs low cardinality fields, skewed popularity, recency bias, multilingual text, and valid relationships between entities. I f you ignore these, and you will see your query plan flip from an index seek in staging to a full table scan in production.
Think of it this way:
- User IDs, order IDs, and emails need to be truly unique, not just random until they collide.
- Low cardinality fields like status should follow realistic proportions (Ex: PAID far more common than CANCELLED).
- Popularity is not actually uniform, some items get hammered while others rarely touched.
- Time is not uniform either, most records may be recent.
- Text is not just ASCII, real systems deal with accents, scripts, and collation rules.
When you model these factors, you reproduce the production issues in the lab, where they are cheaper to fix.
2. A Simple Commerce Model
To make this concrete, let us use a small schema that generalizes well to many systems:
- users(user_id, email, country_code, created_at)
- products(product_id, sku, category)
- orders(order_id, user_id, product_id, status, total_amount, created_at)
- search_logs(ts, user_id, query_text, filters_json)
With just these four tables, you can capture uniqueness, joins, skew, recency, and realistic search behavior. It’s enough to make your performance test meaningful without drowning in complexity.
3. Popularity Skew: Why Uniform Random Fails
If you pick users and products uniformly, your system will breeze through tests. In reality, a few VIP users or hot products dominate. One SKU might account for 40% of sales, while thousands of others barely move. Uniformity hides those problems.
That is why I use a Zipf distribution. It naturally creates hot spots, the most popular items get hit again and again, while the long tail is rarely touched. This is when caches start thrashing, partitions run hot, and locks pile up ,exactly the kind of stress you want to see before go live.
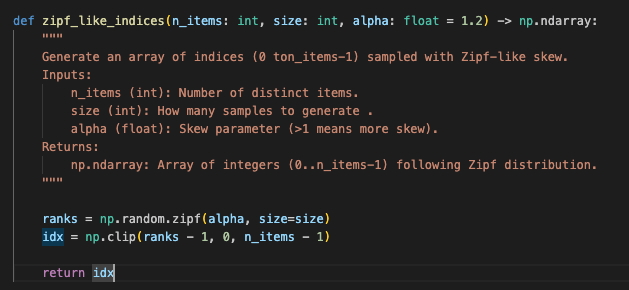
4. Uniqueness: Don’t Gamble With Keys
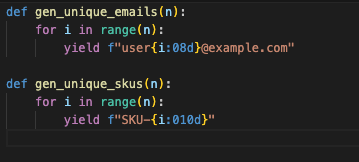
Nothing kills a test faster than duplicate keys sneaking in. It is not a performance bug it is a data bug. Instead of hoping randomness does not collide, build uniqueness in by design, deterministic email generators, SKU (Stock Keeping Unit) sequences, predictable IDs. That way you can scale to millions of rows without fear.
5. Users: Realistic Variety
Fake users should not all look like John Doe. Production users come from everywhere, and their accounts skew heavily toward the recent past. If your test data does not reflect that, your cache and storage patterns won’t either.
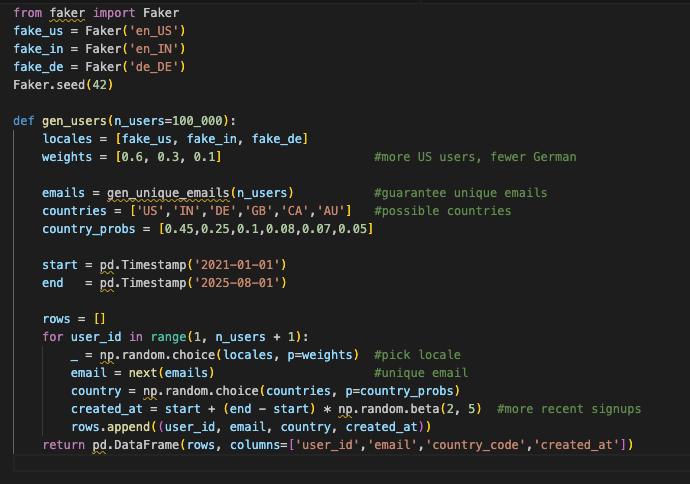
Why bother? Because clustering by time affects indexes and cache locality, and non-English names will surface collation quirks long before production users complain.
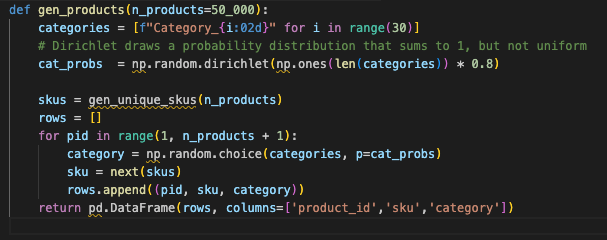
6. Products: Not All Categories Are Equal
In real commerce systems, categories are rarely balanced. A few dominate. Modeling that unevenness exposes whether your indexes really help or just look good in theory.
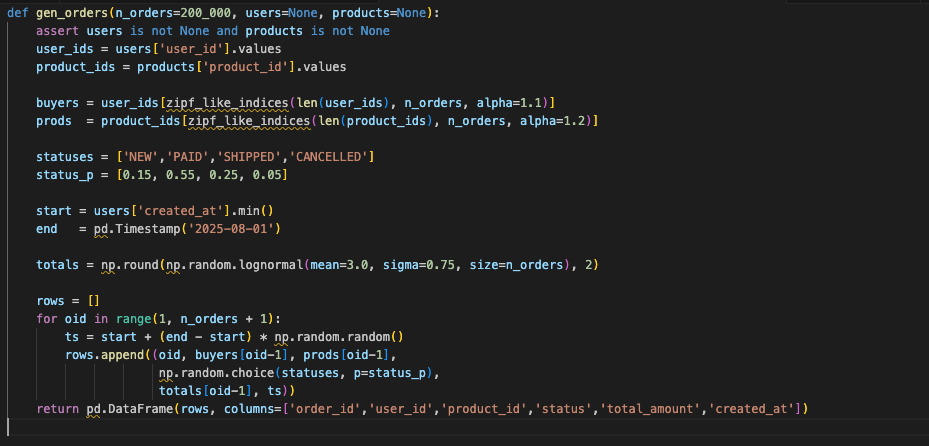
7. Orders: Where It All Comes Together
Orders tie the model together and amplify skew. Use Zipf to decide who buys and what they buy. Keep statuses realistic (PAID dominates). Use a lognormal distribution for totals so you get plenty of small purchases and a few giant outliers that really test your aggregates.
Why it matters:
- Hot buyers and products create real lock contention.
- Status fields stress optimizers.
- Heavy tails in totals push sort and merge operators harder than uniform values ever will.
8. Validate Before You Scale
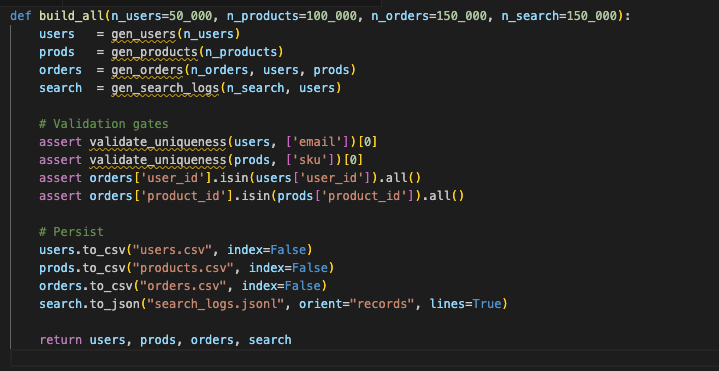
Before you generate millions of rows, validate. Are emails unique? Do foreign keys match? Are proportions roughly what you expect? If not, fix it now. Better to catch it in CI than mid-load test.
9. Export for Bulk Loads
Export in formats your datastore likes best – CSV for simple loads, Parquet for columnar systems. Sort by time if range queries matter. Partition by date or category if your engine prefers it. These little choices make your test setup both faster and more faithful.

Tips that pay off immediately:
- Parquet for columnar stores (Spark, DuckDB, BigQuery).
- Pre-sort by time (created_at) when your engine benefits from clustering or when time-range filters dominate.
- Partition outputs by date/category if your lakehouse or MPP engine prefers directory partitioning.
10. Multilingual Text: ASCII Won’t Save You
If you only test with English ASCII, you will miss the issues. Real users type accents, non Latin scripts, and emoji. Tokenizers and collations behave differently across locales. If your test data does not include them, you are running an optimistic simulation.
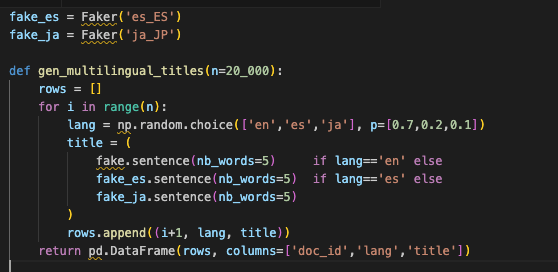
Fold these titles into search scenarios to validate analyzers, highlighting breakers, and query normalization.
11. Orchestrate End-to-End Builds
Package everything behind a single function so teammates (and CI jobs) can produce datasets consistently.
12. Common Pitfalls
- Using uniform random everywhere → looks fine, hides hotspots.
- Small key ranges → duplicates at scale.
- No referential integrity → orphan rows crash your joins.
- Overly clean text → indexes and caches look better than they are.
- Static snapshots only → you miss time-dependent behavior.
13. Why This Approach Works
This method scales down or up: start with 50k/100k/150k rows locally and scale to tens of millions in a cluster. It turns fake data into a signal amplifier that:
- Reproduces production only query plans in staging
- Surfaces contention on hot keys and partitions
- Exercises indexes under realistic selectivity
- Stresses caches the way real traffic does
- Prevents false failures from duplicate keys and broken FKs
Final Thoughts
The biggest step forward you can take in performance testing is not adding more virtual users it is making your data more realistic. Stop generating random fillers, Start generating representative datasets that mirror the quirks of production i.e skew, recency, uniqueness, language variety. Do that, and your load test stops being a demo. It becomes a dress rehearsal you can actually trust when launch day comes.
About the Author
Sudhakar Reddy Narra is a Performance Engineering Architect with 17+ years of experience in designing scalable, high performing enterprise systems. He specializes in cloud infrastructure, microservices, JVM optimization, database tuning, observability frameworks, and synthetic data generation. His work consistently enhances scalability, reliability, and cost efficiency across diverse industries and platforms.
Nice Article
Nice post. I learn something totally new and challenging about creating data for performance testing.
This is very good post for performance engineers to create the data
Thanks a bunch for sharing this article on data creation for performance testing with all of us. The author actually knows what you’re talking about!