
If testing used to feel like checking a single house, modern testing can feel like inspecting a whole neighborhood while the builders are still pouring concrete.
That’s why teams increasingly rely on lightweight, always-on tools, including mobile-facing companions like Lively for iPhone, to surface issues closer to where users actually experience them. Today’s apps are packed with microservices, cloud services, third-party APIs, and AI features that don’t always behave the same way twice.
That complexity shows up in the daily pain: more moving parts, releases that happen every day (or every hour), flaky tests that fail for no clear reason, and a bigger security blast radius when something slips through.
This post takes a practical look at how software testing and software quality assurance are changing in 2026.
Why complex applications are harder to test than they used to be
Classic testing habits were built for classic apps: one main codebase, a clear release date, and a test phase near the end. That playbook breaks down when your product is a set of services that ship often and talk over networks you don’t fully control.
Picture a simple checkout.
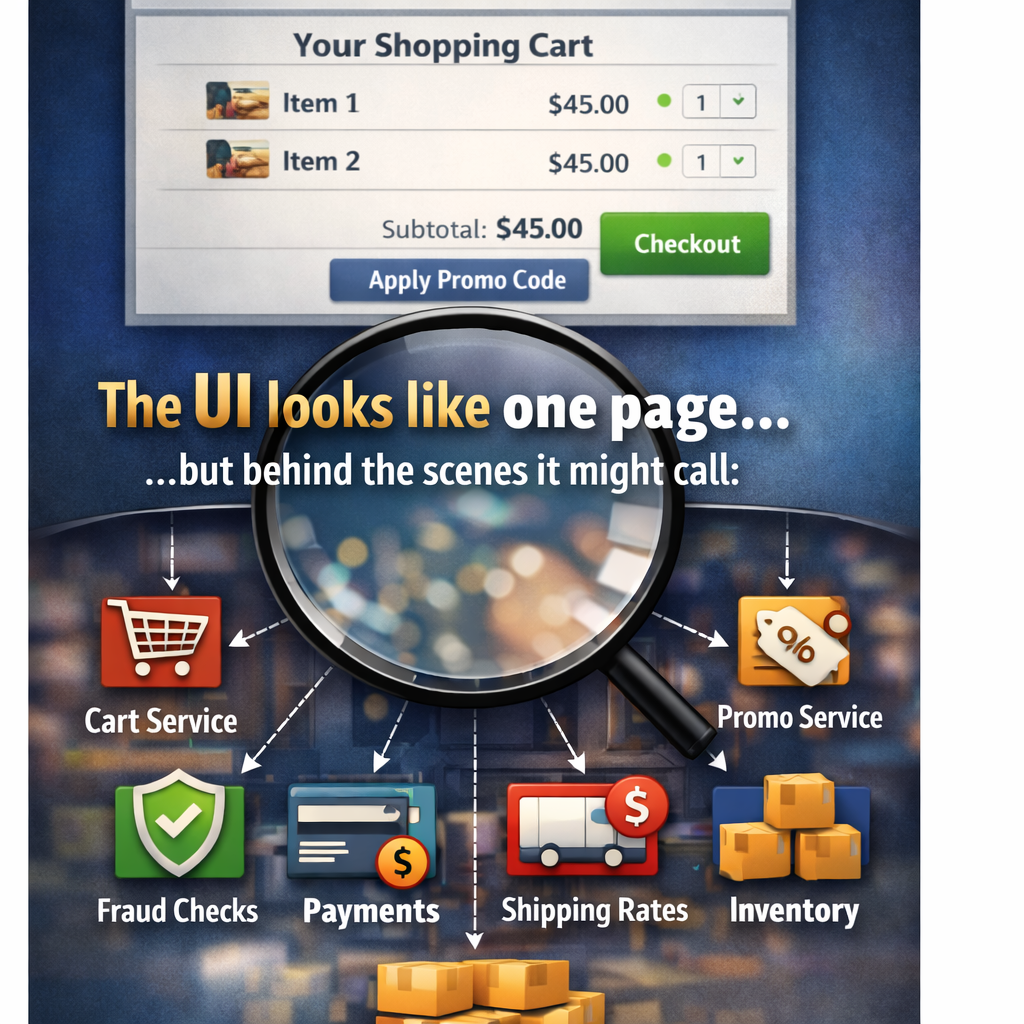
One timeout, one schema change, one “minor” retry setting, and the flow can fail in a way your end-to-end UI test never predicted.
That risk is not theoretical. Nearly 40% of organizations have suffered a major outage caused by human error over the past three years, often from small changes that slipped through testing.
Older approaches struggle for two big reasons:
- Late-stage manual testing finds issues when it’s expensive to fix, and often too late to stop the release train.
- UI-only automation is brittle. It’s slow, hard to debug, and it hides which service actually broke.
Modern QA has to test the system like it really works: many parts, many connections, lots of change, and failure as a normal condition.
Microservices and APIs create more failure points than a single codebase
Microservices sound neat until you try to test them as one product. Each service has its own release cycle, its own data, and often its own team. That creates dependency traps: service A expects one request shape, service B starts returning a new field, and the integration quietly breaks.
Version drift is the classic problem. Your staging environment might have three services on “latest,” two on “almost latest,” and one stuck on an older version because of a hotfix. If your tests only validate each service in isolation, you miss the messy part, the connections.
Cloud and distributed systems fail in messy, real-world ways
In cloud and distributed systems, failures don’t look like clean red errors. They look like slowness, retries, partial results, and odd spikes that only happen in one region at 2:13 p.m.
Latency changes. Requests time out. Queues back up. A third-party API returns 503 for five minutes. An autoscaling event adds new instances that don’t have warm caches yet. Your app might still be “correct,” but it’s not usable.
Modern testing practices that keep up with fast releases and constant change
In DORA’s benchmark bands, ‘elite’ teams deploy on-demand (many deploys per day) and have lead time under a day, which makes continuous testing less optional and more survival.
For modern quality assurance teams, that pace changes the job itself, from catching bugs at the end to continuously managing risk across the delivery pipeline.
Testing in 2026 is less about one big test phase and more about continuous testing across the delivery pipeline. The goal is fast feedback, stable integrations, and a test suite that doesn’t eat your week with maintenance.
This is where teams are landing: earlier checks (shift-left testing), more API coverage, contract testing for service boundaries, smarter risk-based testing, and self-healing test automation to cut the “why did this test fail again?” grind.
Shift-left and continuous testing in CI/CD, so bugs are cheaper to fix
Shift-left testing is simple in spirit: run meaningful checks as close to the code change as possible.
A practical CI/CD split many teams use:
- On every pull request: unit tests, API tests for the changed service, static checks (linting, security scans), and fast smoke checks.
- On merge to main: broader integration tests, contract checks across dependent services, and a small set of end-to-end flows.
- Nightly (or scheduled): longer performance suites, chaos or failure tests, and deeper security checks that would slow down daytime builds.
API-first and contract testing to stop integration surprises
API-first testing treats the API as the product, not just a helper behind the UI. When microservices drive the app, API tests give you faster runs, clearer failures, and less UI fragility.
Contract testing adds a guardrail between teams. A contract is a simple promise: request fields, response schema, status codes, and rules about what counts as a breaking change. Providers prove they meet the contract, and consumers prove they can handle the responses they expect.
Risk-based testing replaces the fantasy of full coverage
Full coverage sounds comforting, like buying every insurance policy at once. It’s also unrealistic for complex apps with constant change. Risk-based testing is how teams stay honest: you pick tests based on impact and likelihood, then you run the most important checks first.

Leave a Reply