
Delivering anonymized, production-like test data to QA environments is one of the most time-consuming and error-prone tasks in modern software development. Manual scripts, static datasets, and cloned production databases not only delay releases, but also expose organizations to privacy and compliance risks. The root problem lies in the lack of automation and security in how test data is prepared and delivered. Without standardized processes, teams rely on manual intervention, increasing the likelihood of human error, inconsistent data quality, and regulatory non-compliance. This makes testing slow, unreliable, and risky.
Author: Sara Codarlupo
This article walks through how engineering teams can automate the delivery of anonymized test data-ensuring speed, compliance, and scalability in CI/CD pipelines-by leveraging modern test data management practices.
The Complete Workflow: Delivering Anonymized Test Data in Practice
With Gigantics, the process of delivering anonymized test data can be fully automated. Here’s how it works in a typical CI/CD environment:
Gigantics starts by analyzing database schemas and comparing them with previous versions. This allows the platform to detect structural changes and prepare for accurate data handling.
To support this process, Gigantics also enables data provisioning as a core functionality-allowing teams to efficiently extract, transform, and deliver the right volume of test data to any environment.
It then performs automated data discovery, using AI-driven recognition and metadata analysis to identify and classify sensitive fields such as names, emails, and IDs. This ensures consistent PII detection across data sources and eliminates the need for manual field mapping.
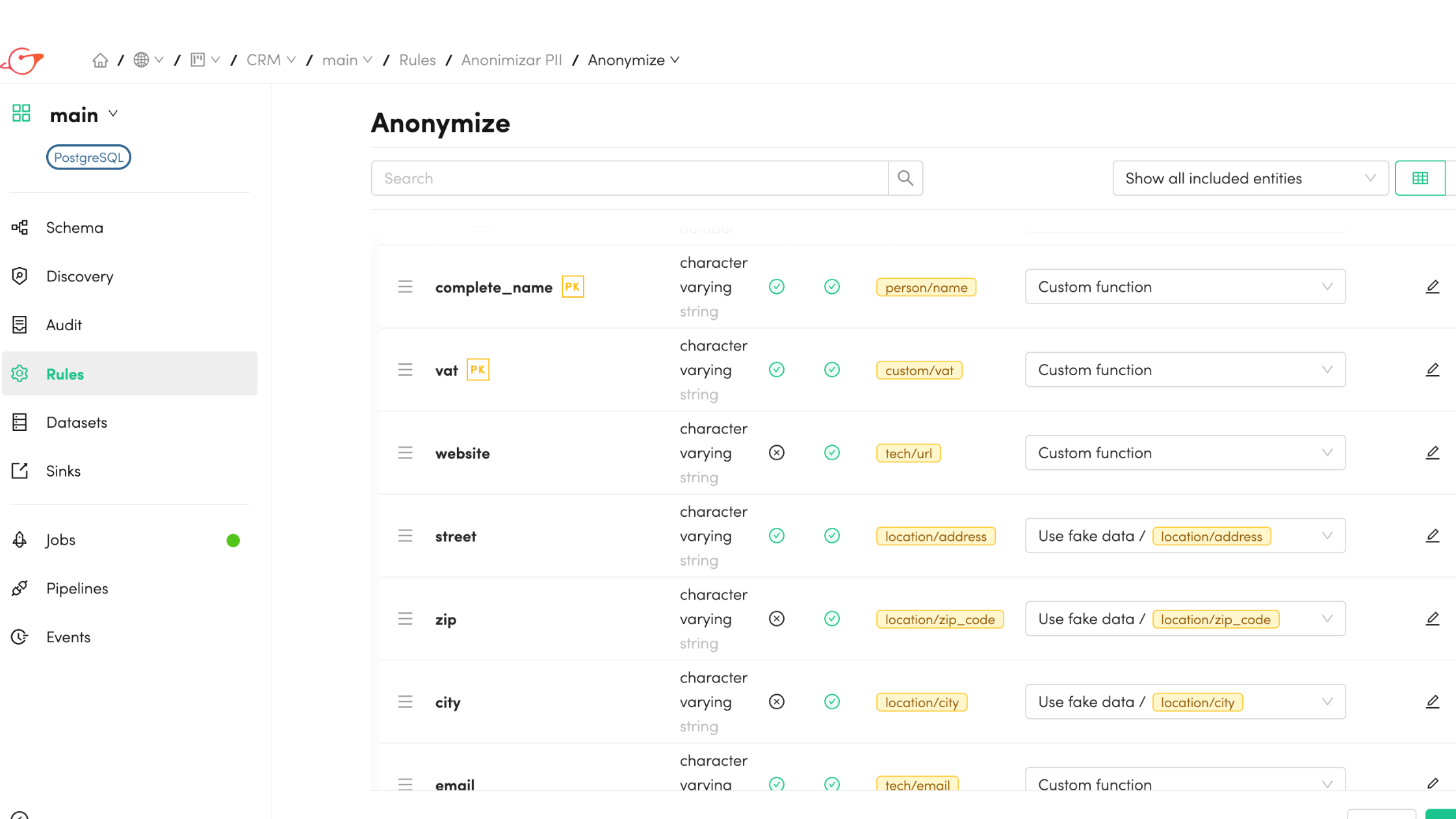
Once sensitive data is identified, users can apply anonymization rules directly within a Model. Gigantics offers several methods:
- Fake data +: Converts real values into realistic but fictitious values based on the field’s label.
- Functions: Includes Mask, Shuffle, List, Delete, and Blank. For example, the Mask function can transform text, replace characters, or apply regex patterns. Shuffle randomizes column values, and Shuffle Group randomizes values across multiple columns while keeping relationships.
- Saved functions: Allows reusing previously defined transformation logic.
- Custom functions: Users can define and apply their own transformation rules.
- No action: Leaves the field unchanged.
After anonymization, the transformed data is securely delivered into your test environments through native integration with CI/CD tools like Jenkins, GitLab CI, or GitHub Actions. This ensures that every test execution starts with fresh, compliant data-without manual intervention.
In addition to these core functions, Gigantics provides:
- Identification of PII elements and risk analysis for each field.
- Generation of PDF security reports.
- Management and download of datasets.
- Dumping of datasets into target databases.
- Secure deployment to multiple environments.
- A system of roles and permissions aligned with enterprise structures.
The platform organizes work into Organizations and Projects. A Project includes one or more Models, each linked to a data source (or ‘tap’). Within a Model, users access a structured set of modules designed to support the full test data lifecycle. These include tools for reviewing schema versions, scanning and classifying data fields, defining transformation rules, auditing risks, generating datasets, configuring data destinations (sinks), orchestrating pipelines and jobs, and tracking user activity throughout the process. Tracking of user actions.
Impact for QA and DevOps Teams
Automating the delivery of anonymized test data isn’t just about convenience-it’s about enabling core capabilities:
- QA teams gain consistent access to compliant, high-quality data, eliminating dependencies on DBAs or shared staging environments. This accelerates test cycles and improves reliability.
- DevOps pipelines benefit from reduced manual steps, tighter integration, and audit-ready logs at every stage. Security and compliance controls become part of the delivery process, not an afterthought.
Ultimately, the ability to provision secure, anonymized test data on demand allows organizations to release faster, reduce operational risk, and scale testing without sacrificing control.
Test data shouldn’t be a blocker-or a risk. With the right automation, QA environments can be safely and instantly populated with anonymized data that reflects production complexity without exposing real users.
Gigantics is purpose-built for this. By combining schema analysis, PII discovery, policy-based anonymization, synthesis, and CI/CD integration, it transforms test data into a secure, scalable service – not a bottleneck.
About the Author
Sara Codarlupo is a marketing and content strategist specialized in technology and software testing. She helps tech companies communicate the value of their products through clear, useful content tailored to QA and DevOps.