
As distributed systems are too complex for deterministic testing, AI can help. In this article, Naveen Prakash proposes an approach based on the ideas of chaos engineering and AI-assisted testing. The focus shifts from testing individual pieces to understanding what happens when many services run together under unpredictable conditions.
Author: Naveen Prakash, QA Automation Architect & AI Testing Practitioner
Knowing the Issue
Imagine getting through an inventory check and somehow ending up with ‘never updated’ stock levels. A wrong inbox receives confirmation of an order. You run your unit tests — everything passes. Nobody’s broken. That’s the flavor of failure that makes these problems so hard. Because the bug’s not planted anywhere. It’s in the links.
Modern systems are a tangle — databases, caches, messaging queues, microservices, API gateways, all talking to each other in a constantly shifting dance. A single user request might touch six or seven of these before it resolves. Tests usually check each piece in solitude, which is fine until you realise production does not run in solitude. Things slip through the cracks not because any single service broke, but because nobody thought to test what happens when two seventy-per-cent-correct behaviours land at the same time.
Cache inconsistencies, retry amplification, async message reordering — the usual suspects. Gartner research suggests a large chunk of distributed system failures trace back to exactly these.
Launching CLSSM
The above model Cross-Layer Synthetic Scenario Modeling (CLSSM) can be used to ‘Twitch’ this. Perhaps it’s better to think of CLSSM as a structured practice – based on the ideas of chaos engineering and AI-assisted testing, rather than as a proper industry term.
The focus shifts from testing individual pieces to understanding what happens when many services run together under unpredictable conditions.
Figure 1 shows how the Engineering and Operational Modes of an AI system interact and feed into each other.
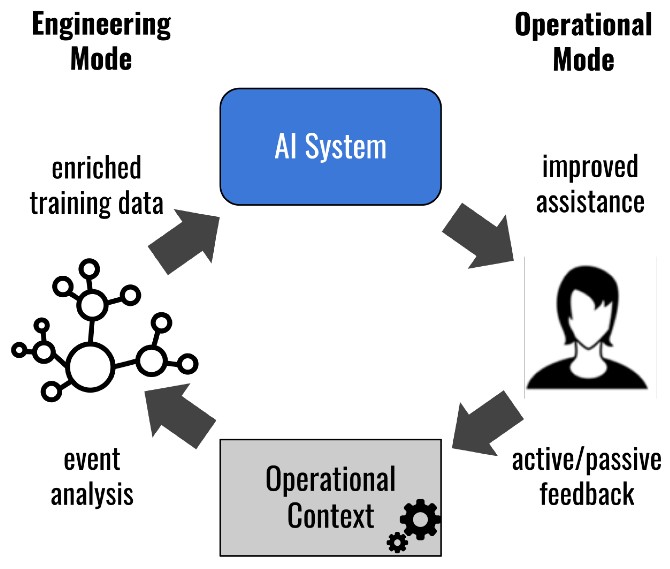
Figure 1: interaction between the Engineering and Operational Modes of an AI system
Modeling System Interactions
Before you can reliably test how your system fails, you need an honest understanding of how it works. Not the architecture diagram you drew last month — what’s really happening in production right now. Add OpenTelemetry instrumentation to your services and start capturing distributed traces. Pipe them into Jaeger or Grafana Tempo. What comes back is usually surprising. Teams regularly discover call paths that nobody documented — a synchronous call hiding inside an async flow, a retry chain that fans out to four services, a cache dependency that wasn’t in anyone’s mental model.
Figure 2 shows how user input flows into an LLM, through any supporting tools such as file systems or APIs, and back out as a response.
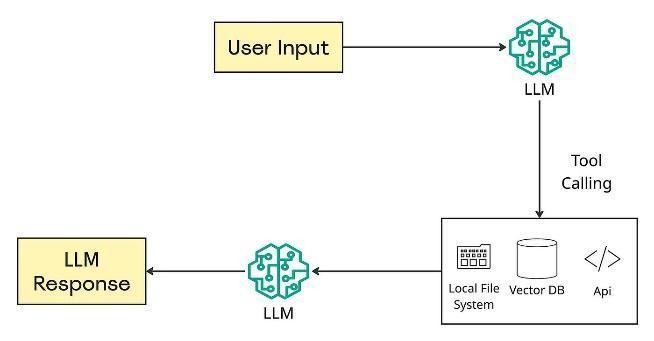
Figure 2: interaction between user input and the LLM
Generating and Running Scenarios
When the graph’s in hand, you’ve got to make your incision. Run your trace data through an AI model – a simple clustering or anomaly detection rig will do for starters – and have it rank paths based on error rate, tail latency, or how many services they touch downstream. The higher any of the scores are, the more likely you’ve found the place to start. You design scenarios: slow down a dependency by 800ms and see what happens, trigger rapid retries to one service and watch whether the cache behind it buckles, reorder a batch of async messages and check if the downstream consumer manages. You’re hunting for the stuff that’s been quietly broken for months and nobody noticed.
Execution – use tools that allow you to delay or degrade specific dependencies rather than just killing whole services. Slow responses, dropped connections, artificial timeouts – that’s much closer to real production degradation. Netflix has written on failure testing at length, and the underlying premise is still a sound one – break things before they get broken on you in front of users.
Figure 3 shows an AI-based analytics platform with specialised agents handling detection, analysis, and decision support across cloud infrastructure.
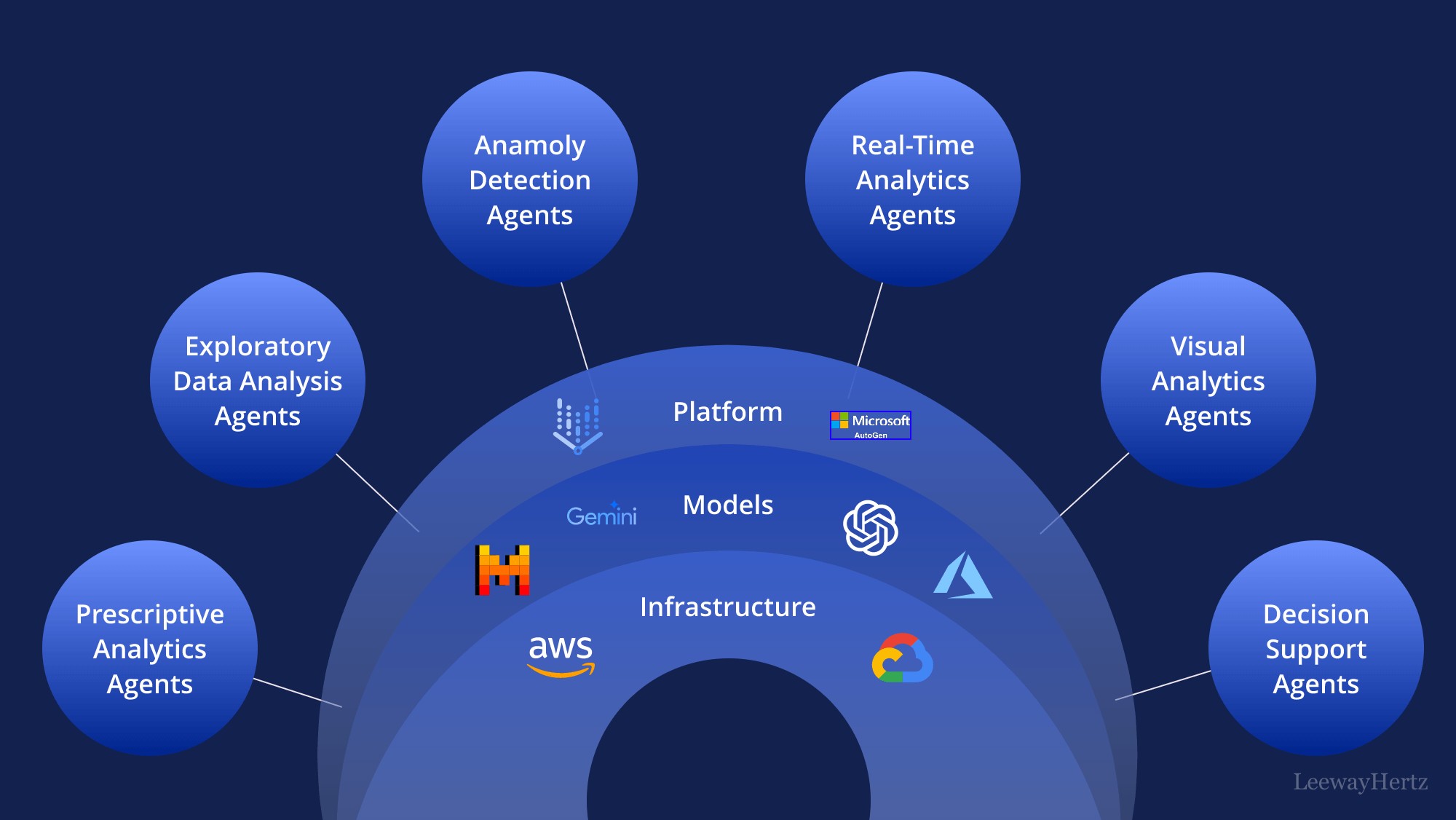
Figure 3: AI agents for data analysis: Types, working, mechanism, use cases, benefits, implementation
Table 1: Contrasting Testing Methods
| Methodology | Coverage | What It Supports | Restrictions |
| Unit Testing | One component | Logic correctness | Constricted to lone conduct |
| Integration Testing | Service pairs | Validating API | Partial coverage of the system |
| End-to-End Testing | Workstream | Business workflows | Usually assumes perfect conditions |
| AI-assisted CLSSM | At levels of the system | Actual interactions | demands observational and computer investment |
Putting CLSSM Into Practice: A Step-by-Step Guide
Here is how a real team can get started without overhauling their entire testing infrastructure at once.
Step 1: Instrument your services with OpenTelemetry
Drop the OpenTelemetry SDK into each service and get distributed tracing working — every cross-service call needs a trace ID so you can follow a request end to end. Pick a collector: Jaeger, Zipkin, Grafana Tempo all work. Two or three days of live traffic is enough to start seeing patterns. If wiring everything at once feels like too much, start with your two or three busiest integration points.
Step 2: Build the interaction graph from real trace data
Go through your trace data and extract the service-to-service call relationships. If you’re on a service mesh Kiali does this almost automatically, otherwise a short Python script over your exported span data works fine. What you want at the end is a graph where every node carries three numbers: average latency, error rate and call volume. The connections you care most about are the ones with a messy combination of these – high errors, lots of downstream dependencies, or calls keep timing out. That’s where you focus first.
Step 3: Use AI to dig up scenarios your team wouldn’t think to write
Make the graph, stick it in front of an LLM or rule-based analyzer. Something like: “Here are our service dependencies and their observed error patterns. What are ten failure scenarios that unit and integration tests would miss?” The results are often better than you’d expect. Specific, plausible situations — payment service hammering the inventory cache with retries during peak load, notification queue piling up silently because email provider is slow, order confirmations arriving out of sequence as a result. These aren’t hypotheticals. They’re runnable test cases built from your actual system data.
Step 4: Run it — with the right fault injection setup
If you’re on Kubernetes, Chaos Mesh and LitmusChaos are both good options — write a YAML config, define what you want to break (pod failures, network delays, CPU pressure), and bring on the pain. Not on Kubernetes? Toxiproxy is worth knowing about. It’s a little proxy that you put in front of HTTP or TCP connections — then you can throttle bandwidth, introduce lag, or kill the connection entirely, without changing your infrastructure. Before each run, write down your baseline: error rate, latency, throughput. Without that, you have no idea what “recovered” actually means.
Step 5: Watch the numbers that actually matter
As each scenario runs, keep an eye on these five: error rate at every service boundary involved, p99 latency on the impacted path, retry counts, queue depth, and time to recover once the fault clears. That last one — how quickly does it bounce back? — is usually the most revealing. Track these across runs and patterns emerge. Some parts quietly improve. Some slowly degrade. Both matter.
Practical Concerns
One of the strengths of CLSSM is its feedback loop — when a scenario surfaces unexpected behaviour, that path gets deeper attention in the next cycle. Testing effort naturally shifts toward the most failure-prone areas over time.
That being said, the approach is built on solid observability practices and potentially can incur extra overhead. For teams that are still relatively new to adoption, the pragmatic route is usually to focus on a handful of critical processes.
Figure 4 shows the four-stage feedback loop — Design, Collect, Analyze, Respond — that drives continuous improvement in the CLSSM approach.
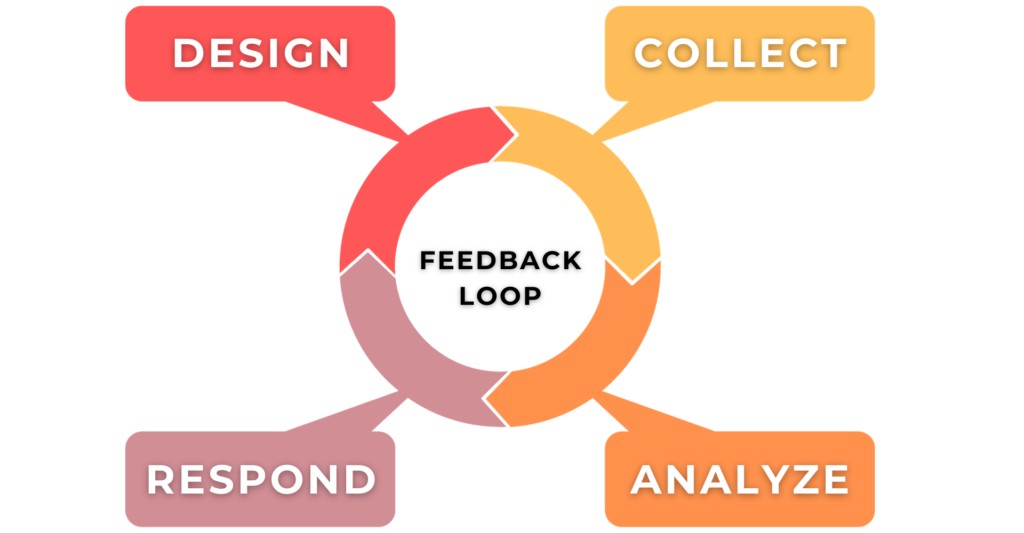
Figure 4: feedback-loops-in-training-program-evaluations
In conclusion
Distributed systems are too complex for deterministic testing alone. The real question is whether your current validation approach can catch interaction-related failures before they show up in production.
It’s not a question of whether one of these failures will happen, but when (and if we can catch the failure during testing or only after we’ve used it)
References
1. Citations Gartner. “Distributed Systems Reliability and the Cost of Cross-Service Failures.” https://www.gartner.com (2023)
2. “Chaos Engineering.” Netflix Tech Blog, 2016. https://netflixtechblog.com/chaos-engineering-upgraded-878d341f15fa
3. OpenTelemetry Documentation. https://opentelemetry.io/docs/
4. Principles of Chaos Engineering. (2019). Available at: https://principlesofchaos.org
About the Author
Naveen Prakash is a QA Automation Architect who lives and breathes distributed and AI-driven systems. Day to day, he builds the kind of test automation that actually holds up in production — working across UI, API, and backend layers with tools like Playwright and Selenium. A good chunk of his work involves making tests smarter: generating them intelligently, validating across multiple application layers, and using runtime analytics to catch what static tests miss. When he’s not knee-deep in a system, he writes about what he’s picked up along the way — the real stuff, not the textbook version.
Interesting article about the practical usage of AI in software testing, especially the step-by-step guide.
Interesting conclusion that “distributed systems are too complex for deterministic testing alone”. It could be a right context to use AI and feed a LLM to improve testing. I like the fact that the approach contains a list of tools to use.
Cache inconsistencies are the exact kind of failure that used to kill our SEO without any alert — a stale canonical URL served from one service while the rest of the system moved on. We ended up building a small monitoring layer that detects when the canonical tag served by the frontend doesn’t match what the sitemap generator knows. So far it’s caught three regressions that all unit tests had missed. We use something similar for our own infrastructure.