
As AI makes test creation nearly effortless, software teams face a new challenge: determining which tests actually improve quality and which simply add noise.
Author: Eli Lopian
For years, software teams focused on a simple goal: write more automated tests.
The industry invested heavily in testing frameworks, mocking libraries, CI/CD pipelines, and code coverage tools. The logic was straightforward. More tests meant fewer defects, safer releases, and greater confidence when changing code.
That strategy worked. Modern applications often contain thousands of automated tests. Builds run on every commit. Coverage reports have become a standard quality metric. Automated testing is now a fundamental part of software development.
But AI is changing the equation.
Today, developers can generate dozens of unit tests in seconds using AI coding assistants. What once took hours can now happen almost instantly. As a result, the challenge is no longer creating tests. The challenge is understanding whether those tests actually provide value.
A generated test may compile, execute successfully, and increase code coverage. Yet none of those things guarantee that it improves confidence in the software.
That raises an important question: who reviews the tests?
The New Bottleneck
The software industry has spent years solving the problem of test generation. It may now need to focus on test evaluation.
Traditional testing metrics offer only part of the picture. Code coverage tells us which lines of code were executed. Build reports tell us whether tests passed. Test counts tell us how many tests exist.
What these metrics do not tell us is whether the tests are good.
Two projects can report identical coverage while providing very different levels of confidence. One may contain well-designed tests that validate meaningful behavior and fail only when something important changes. The other may contain duplicated tests, weak assertions, and tests tightly coupled to implementation details.
From a dashboard perspective, they look the same.
From an engineering perspective, they are not.
Why AI Changes the Conversation
This distinction becomes increasingly important as AI-generated tests become more common.
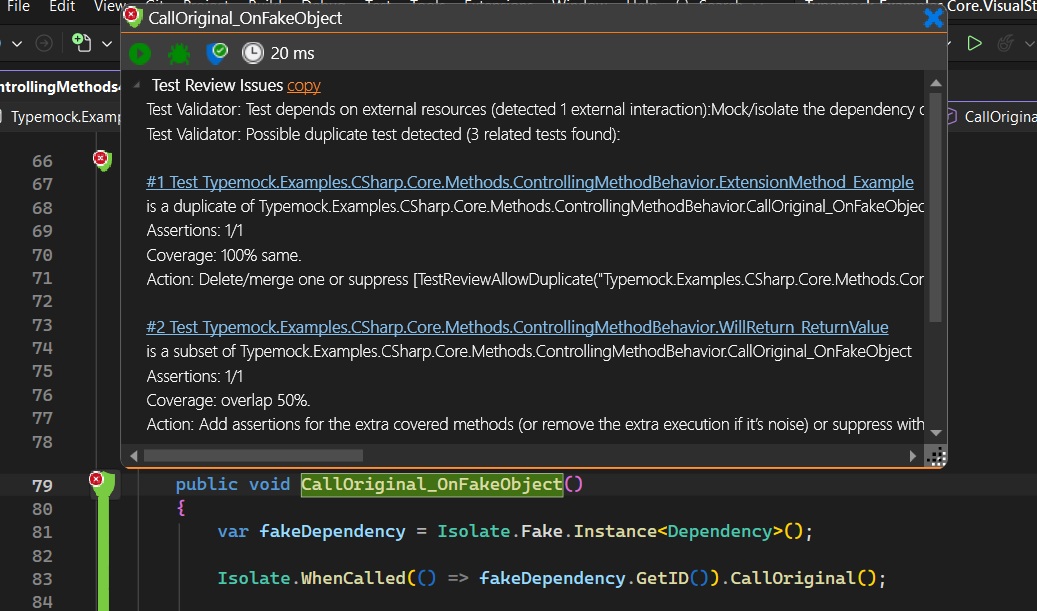
Large language models are remarkably good at producing test code. They can identify methods, create mocks, and generate assertions with impressive speed. However, they optimize for generating plausible test code, not necessarily valuable test suites. Imagine an AI assistant generates five new unit tests. All five pass. The pull request looks healthier. Yet all five tests validate essentially the same behavior using slightly different inputs and assertions. The team now has five tests to maintain, but only the confidence of one. Traditional testing metrics celebrate this outcome. Test quality analysis reveals a different story.
As a result, AI-generated tests often exhibit familiar patterns. Many verify implementation details rather than observable behavior. Others duplicate coverage that already exists elsewhere in the suite. Some contain assertions that technically pass but provide little protection against defects.
The tests look legitimate.
The question is whether they are useful.
This is not just an AI problem. It is a testing problem that AI is making more visible.
When More Tests Become Technical Debt
Many organizations already struggle with large test suites that have accumulated over years of development. Tests are rarely deleted. New ones are constantly added. Over time, teams inherit thousands of tests that few developers fully understand.
The assumption is often that more tests automatically mean higher quality.
In reality, every test carries a cost.
Tests must be executed, maintained, reviewed, and updated. They can slow build pipelines, create false failures, and increase the effort required to refactor code. A test that no longer provides meaningful value can become technical debt just as easily as poorly written production code.
The Hidden Problem of Fragile Tests
One of the most common examples is test fragility.
A test may pass consistently for months and then suddenly fail after a harmless refactoring. The application still works correctly, but the test was coupled to an implementation detail rather than the behavior that users actually depend on.
Developers encounter these situations frequently. Eventually they begin asking whether a failed build represents a real defect or simply another unreliable test.
Once that doubt appears, confidence in the test suite begins to erode.
Runtime Behavior Matters
Another challenge involves hidden dependencies.
Unit tests are expected to run in isolation, yet many quietly depend on external resources. A test may access the file system, depend on the current time, rely on machine-specific configuration, or make network calls without developers realizing it.
Everything works perfectly on the original developer’s machine. Problems appear later in CI environments, containers, or cloud-hosted build systems.
These dependencies are often difficult to identify through source code inspection alone because the issue is not how the test is written. The issue is how it behaves when executed.
This is where the industry may need to rethink how test quality is measured.
For years, test analysis has focused primarily on static inspection. Static analysis remains valuable for identifying code smells and maintainability issues, but many testing problems only become visible at runtime.
A test can appear perfectly reasonable in source control while exhibiting problematic behavior during execution. It may use mocks that are never exercised. It may interact with external systems. It may duplicate the behavior of several other tests. None of these issues are easily captured by traditional metrics.
As test suites continue to grow, understanding runtime behavior may become just as important as understanding source code.
The Next Evolution of Software Testing
The broader challenge is that software testing has entered a new phase.
The first era focused on getting developers to write tests. The second focused on automation and continuous integration. The third emphasized coverage and execution speed.
The next phase may focus on test quality itself.
AI is accelerating this shift because it removes many of the barriers to creating tests. When tests can be generated almost instantly, quantity becomes less meaningful as a measure of progress.
The question is no longer whether teams can generate more tests.
The question is whether they can identify the tests that genuinely improve confidence.
That may ultimately become one of the most important testing challenges of the AI era. As test generation becomes increasingly automated, the value will not come from creating more tests. It will come from understanding which tests matter, which tests can be trusted, and which tests are simply adding noise.
For software teams, that represents a fundamental change in perspective.
For decades, the industry measured testing success by asking, “Do we have enough tests?”
The next goal may be learning how to evaluate them.
In the AI era, the more important question may become: “Can we trust the tests we already have?”
About the Author
Eli Lopian is founder and CEO of Typemock, a provider of AI-powered unit testing and code quality solutions for .NET and C++. With more than 20 years of software engineering leadership, he specializes in unit testing, Agile, TDD, and AI-assisted development. He is also the author of AIcracy: Beyond Democracy.
Leave a Reply