
‘early Model Based Testing’ (eMBT) is a software testing approach that aims to optimize the test case design phase. The first part of this article presented the exploring and review phase of this approach. This article presents the generation of test cases from the model and their execution.
Author: Silvio Cacace, TestCompass, www.compass-testservices.com
3. Coverage phase
When the test model is made, discussed and assessed by the whole team, the test cases can then be automatically generated, based on the agreed test coverage. The agreed test coverage can be the result of a previously performed product risk analysis where the various functionalities are categorized according to priority. Or on an ad hoc risk analysis, performed in collaboration with the business.
In the eMBT tool it is possible to generate the test cases automatically, based on a pre-selected test coverage form, from weak to strong. The following test coverage forms are available.
- Node coverage
All nodes in the model will be tested at least once. The Action/State, Decision and Result symbols are classified as nodes.
- Edge coverage
All edges in the model will be tested at least once. The Yes- and No-path links out of the Decision node are classified as edges.
- Multiple condition coverage
All multiple conditions will be tested at least once. A multiple condition is a combination of 2 consecutive test paths (Yes- and No-path out of a decision).
- Path coverage
All possible paths from Start to End will be tested.
After the agreed test coverage is selected, we can easily generate the test cases, which will be shown on the left side of the test model.
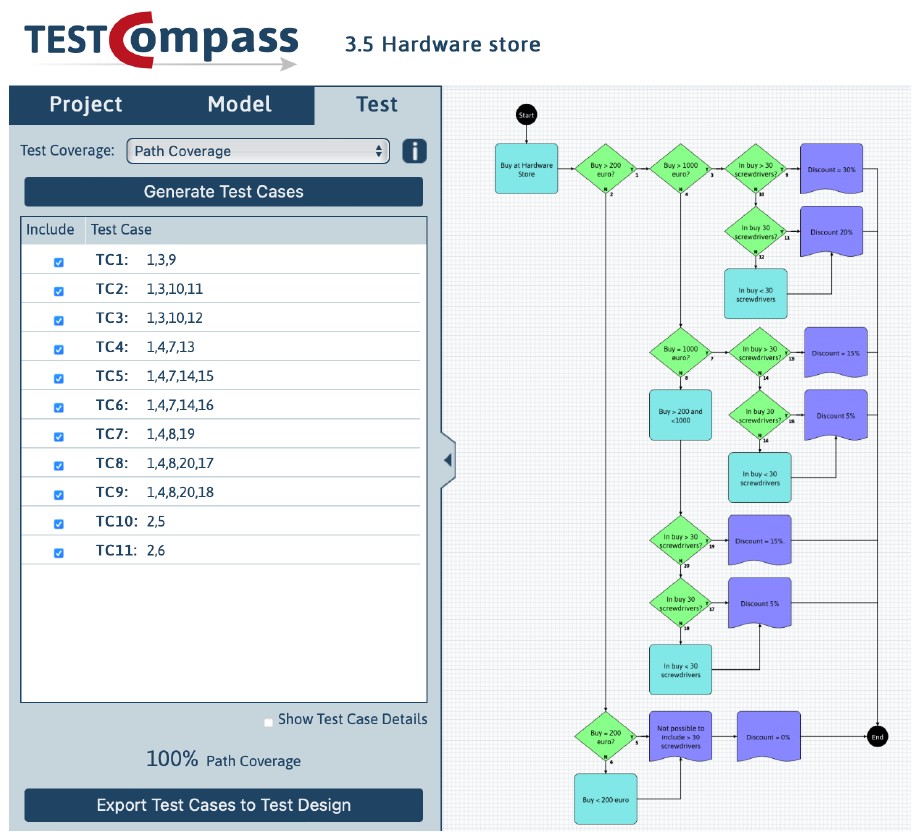
11 test cases were generated based on our test model. The used test coverage is ‘Path coverage’, which means that we need to execute 11 test cases to test all the possible paths in the test model. The test coverage is 100% and is shown (100% Path Coverage).
At this point, it is possible to deselect one or more test cases. This can be useful if, despite the agreed test coverage, we decide to test with a lower test coverage. After deselection of one or more test cases the percentage of the test coverage will decrease automatically. Therefore, it is always clear what test coverage we have achieved for a certain test.
When the test cases are generated, we can export them to an Excel test design, our compass for test execution. The text in the different nodes and any details entered in the test model, such as the preconditions and test data, will be automatically included in the test design.
It is also possible to model in Gherkin-syntax or to enter the Gherkin syntax in de details of the test model (in this example entered as details), which results in a test design including the ‘given-when-then’ steps. An advantage of this is that you can now derive the various Gherkin feature files from here which you can then use, for example, in the Cucumber framework.
The Excel test design for the first 4 of the 11 test cases looks like this.

Impact analysis
As we know, requirements change continuously and it is therefore important to manage these changes effectively. Not least to avoid false positives and false negatives.
One of the advantages of eMBT is, that if there is a change in the requirements, we only need to update the model. After the test model has been updated and reviewed again within the team (review phase), we can perform the impact analysis within the eMBT tool. Every change (functional and text change) in the test model will automatically lead to the possibility to run the impact analysis, which will show the ‘new’ status of the test case(s); added, removed, updated and unchanged.
4. Checking phase
The last phase is the checking phase. In this phase, we execute the test cases in the system under test (SUT) and check whether the expected result is equal to the result in the SUT. Depending upon the characteristics of the test case, for e.g. time-consuming test, repetitive test (regression), hard to do test, smoke test and risk-related test, we can execute the test cases manually or write automated test scripts to execute them automatically.

Conclusion
35% of all bugs in production can still be traced back to the requirements. And these bugs are almost always related to poorly defined requirements or a lack of understanding around those requirements. To make sure we meet the customer’s needs (business value), we need clear and complete requirements and for all members of the team to have a shared understanding of those requirements. In addition, requirements change continuously and it is therefore important to manage these changes effectively. ‘early Model Based Testing’ (eMBT) is a solid approach to solving these problems and challenges.
‘early Model Based Testing’ (eMBT) is a software testing approach that optimizes the test case design phase. But more important, eMBT stimulates communication between all stakeholders (business and technical stakeholders) with the aim of obtaining a shared understanding of the requirements in an early stage of the SDLC process. To get the best possible result of eMBT, you need a well-organized test process and the right eMBT-tooling that supports that process.
About the Author
Silvio Cacace is a passionate test professional since 1994. He works for Newspark and is the founder of the test approach ‘early Model Based Testing’ and the eMBT tool TestCompass.